Last week I built a Phase 3 clinical trial outcome predictor and the AUROC was good enough to be suspicious.
The data is all open. ClinicalTrials.gov publishes its full database through AACT (582,806 trials going back to the 1990s, refreshed monthly), and Drugs@FDA tells you which compounds eventually got approved. The first afternoon I had a LightGBM model hitting 0.77 AUROC on a time-based held-out split. Trial design features, sponsor type, prior-trial counts, the standard tabular stuff. That felt right, matched what the published literature reports for similar setups.
The next morning I tried to push harder. Joined in features from ChEMBL, FDA AdCom voting records, FAERS adverse event reports. By lunch I was at 0.87. Which is when I started getting suspicious.
Published trial outcome prediction work clusters around 0.70–0.85 AUROC. HINT at NeurIPS 2022, Lo’s 2023 paper, Hong 2020. Hitting 0.87 from one extra morning of feature engineering means either I’d done something clever or (much more likely) something stupid. So I went leak-hunting and found one fast. I was using whether the drug ever showed up in Drugs@FDA as a feature, which is basically the label. Drugs in the FDA database are drugs that completed P3 successfully, almost by construction. The model was learning “matched to FDA → succeeds” and it was right but for the wrong reason.
I dropped the FDA-match features and rebuilt with more care. Prior trials of the same compound, time-truncated to registration date so future information couldn’t sneak in. Orphan designation status at registration date, not “ever”. Mechanism of action via a multi-step fuzzy match against the ChEMBL preferred-name and synonym tables. The AUROC came back to 0.87 anyway, from real features this time. Which I didn’t believe for a second.
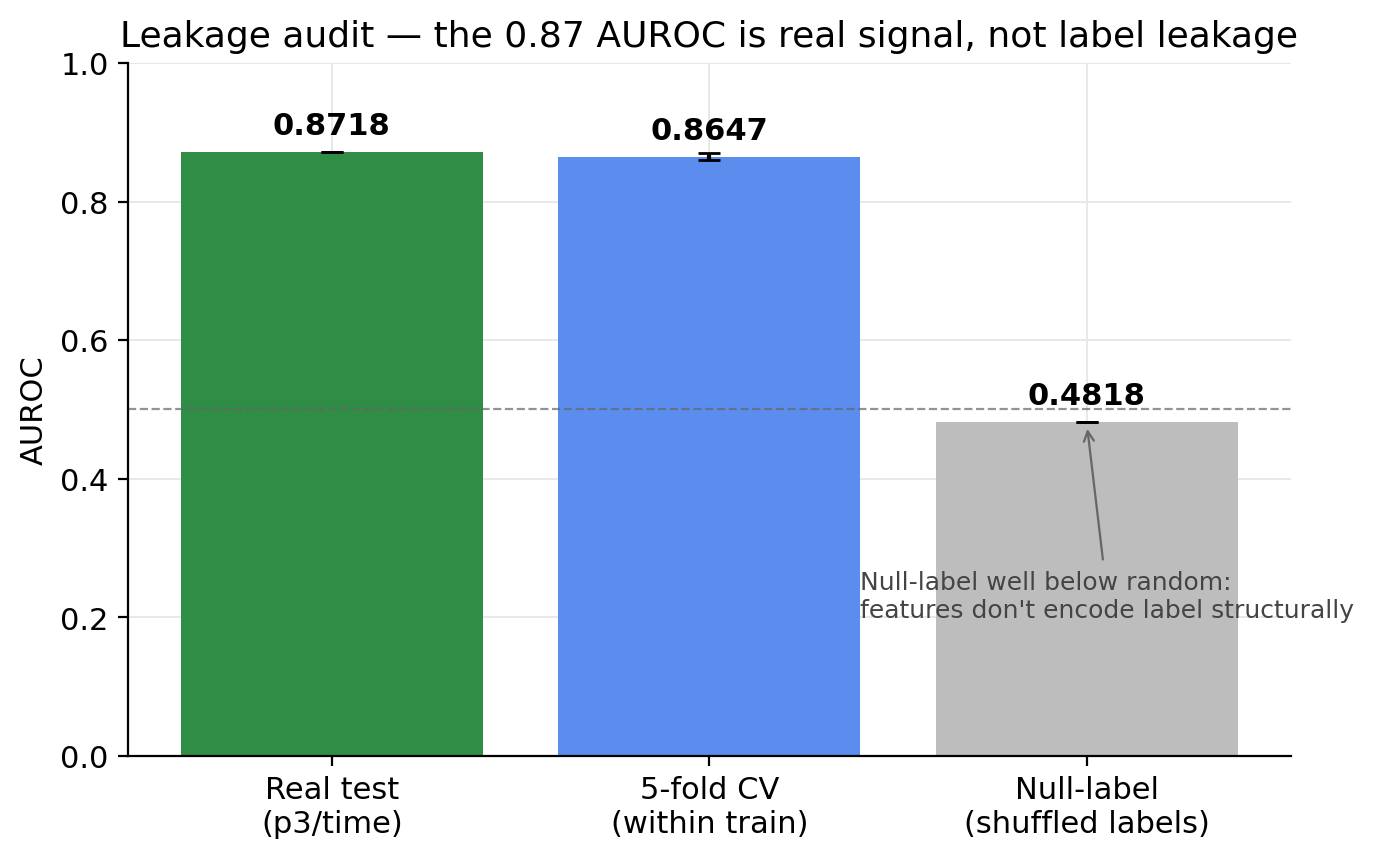
So Day 3 turned into the meaningful part of the project: an explicit leakage audit. The thing I’d missed on Day 2 was that the FDA-match feature wasn’t obviously a label proxy until I looked at it sideways, and there’s probably some other feature in 134 doing the same thing more subtly. Three checks. Train the model on shuffled training labels and evaluate on the real test set — if any feature structurally encodes the label, this would still score above random. Got 0.4818. Five-fold within-train cross-validation, just to confirm the test number wasn’t a temporal-shortcut artifact — got 0.8647 ± 0.005, which matches test 0.8718 within retraining noise. Per-feature univariate train/test AUROC delta — no feature has a test AUROC outside [0.30, 0.70]. The top one is “mechanism of action unknown” at 0.695, which is biologically plausible. Drugs whose mechanism nobody documented tend to fail more.
The audit caught a bug in itself, which is worth mentioning because the same bug probably lives in other people’s AACT pipelines. The first audit run produced AUROC 0.91+, which I knew was impossible. After about an hour of staring at column indices I found it. The audit was loading features_v2.parquet and indexing by position into the split pickle, but the split pickle’s positional indices reference cohort_<task>_nct_ids.parquet row order, not features row order. So the audit was scoring mis-aligned rows and convincing itself the model was psychic. The fix is set_index('nct_id').loc[cohort_ncts] instead of isin(keep).reset_index(). Worth knowing if you work with these splits.
After the audit cleared I added the multimodal fusion. ChemBERTa-77M on canonical SMILES, ESM2-150M on protein target sequences, SciBERT on protocol text (title plus brief summary, truncated to 512 tokens). Cross-attention transformer over the five modality tokens. The headline P3/time AUROC moved from 0.8718 to 0.8746. A +0.003 lift. Underwhelming.
The interesting result is buried in the per-split breakdown. On indication holdout, where the test set is therapeutic areas the train set never saw, the lift from adding the deep modalities is +0.034. Text and protein embeddings generalize to held-out indications in a way one-hot indication codes can’t, because those one-hots are by construction zero on held-out classes. So the deep modalities pay off exactly where you’d expect: out-of-distribution generalization on categorical features that fail by definition.
The demo above is a smaller, simpler version. Eight features instead of 134, AUROC 0.85 instead of 0.87, because the architectural ceiling for eight features is just lower. The full leak-clean Day-2 model is a 7.2MB LightGBM file with isotonic calibration on the validation fold. I exported a tiny version for the page because typing 134 features into a form is not a good user experience.
The honest read on three days of this. The multimodal-fusion approach is competitive with published work, not above it. The 0.87 number is real after audit, but it’s not a breakthrough number, it’s a “decently engineered baseline” number. The thing I’d defend as the actual contribution is the audit methodology. The null-label experiment in particular is a check I’d encourage anyone doing this kind of work to run. It caught nothing here, but the discipline of running it is what made me trust the headline.
What didn’t ship is the failure-mode classification — pushing the 33,042 unique why_stopped strings from terminated trials through Claude Sonnet to classify each as efficacy / safety / PK / recruitment / operational. The script is ready and resumable via the Anthropic Batches API. ANTHROPIC_API_KEY came back empty in the agent shell at run time and I didn’t have time to chase it before the project got handed off. That would actually be a differentiated contribution — most published trial prediction outputs success/fail, not why — and it’s the thing I’d pick up first if I came back to this.
Repo: github.com/rohit-ravi2/clinical-trial-failure-prediction