A CNN classifier trained on the Kaggle Human AI Artwork Dataset (270k+ images across 47 style categories) that answers three progressively harder questions — is this image AI-generated; which generator made it; and what style is it in — while making its decisions inspectable.
Try it in your browser
Everything runs locally via ONNX Runtime Web — the image never leaves your device. The saliency overlay is produced by sliding a 24×24 gray occlusion patch across the image and measuring how much the predicted-class confidence drops when each region is blocked.
Results
| Task | Classes | Top-1 | Top-5 | F1 |
|---|---|---|---|---|
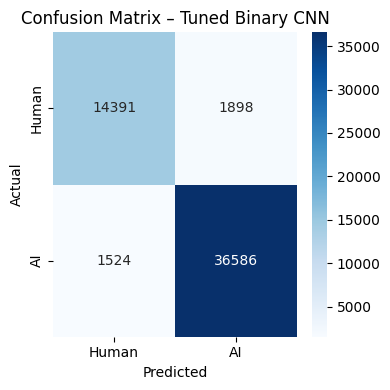
| Binary (Human vs AI) | 2 | 93.71% | — | 0.94 |
| Grouped (AI_SD / AI_LD / DiffusionDB / Human) | 4 | 92.85% | 99.42% | 0.93 |
| Flat style classification | 47 | 44.38% | 84.22% | 0.39 (weighted) |
Tuned architecture: 3 conv layers (32 → 64 → 64), batch norm, L2, dropout 0.42, lr 0.005.
Interpretability
Three lenses on what the model learned:
- Grad-CAM — spatial attention maps per image, useful for checking whether the model keys on brushstroke-level features vs. composition-level ones.
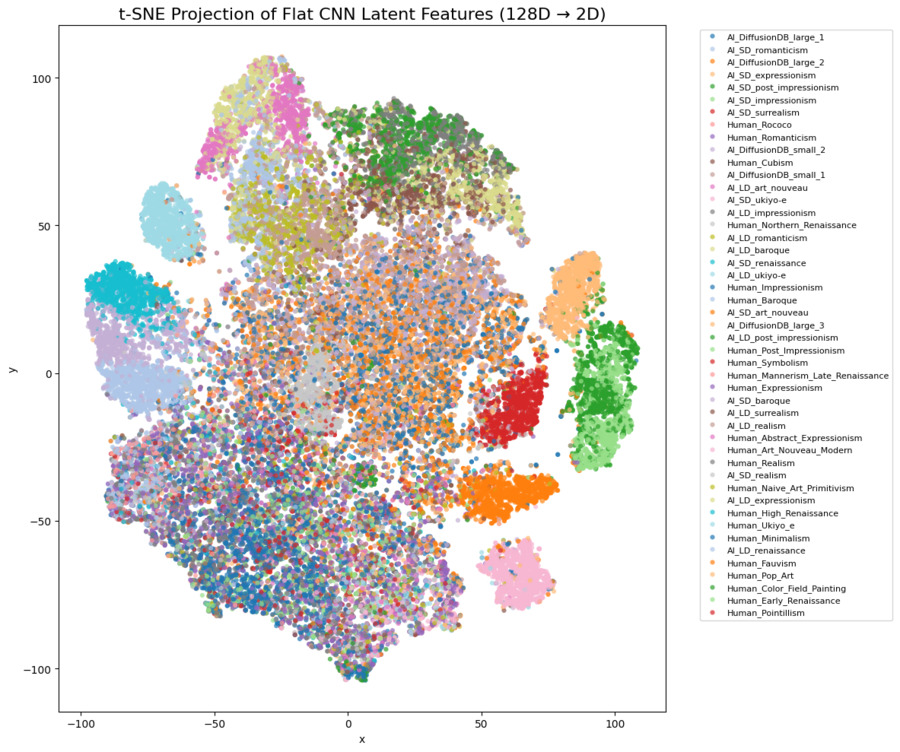
- t-SNE / PCA on the penultimate layer — clusters separate AI generators cleanly; human styles overlap more.
- Style prototypes — per-class nearest neighbors to the class centroid, which surface what each style “looks like” to the model.
Takeaways
- The binary AI/Human signal is strong and largely texture-driven.
- Grouped classification of which AI engine generated an image is nearly as easy as binary detection — different diffusion pipelines leave different fingerprints.
- 47-way style classification is genuinely hard (0.39 F1); the model falls back to broad-class cues when style cues conflict, which is visible in the confusion matrices.
Code: github.com/rohit-ravi2/visual-classification-ai-vs-human-art